What Actually Happens When You Use a Proxy — And Why Reverse Proxies Power Almost Everything
Most engineers have heard both terms. Few can explain the actual difference at the network layer. Here’s the one definition that makes everything click.

The one insight that unlocks everything
When your application talks to another server, two things happen at two different layers.
At Layer 4 (TCP), your machine opens a connection to an IP address. This is the transport handshake—the two machines agreeing they can communicate.
At Layer 7 (HTTP), your application sends the actual message — the GET request, the headers, the body — over that already-established connection.
Here’s the thing most engineers miss:
Those two layers can point at different machines. A TCP connection can land at one server, while the HTTP payload inside it is addressed to another entirely.
That single fact is what makes proxy and reverse proxies possible—and fundamentally different.
What is a forward proxy?
Definition: A proxy is a server that makes requests on your behalf. You know the final destination. The destination doesn’t know you.
Here’s what that looks like in practice. You want to reach google.com. Your machine is configured to use a proxy. Instead of connecting directly to Google, your TCP handshake reaches the proxy server. The HTTP message inside says GET google.com — your intended destination.
The proxy receives the request, then opens a new TCP connection to Google. From Google’s perspective, the request is coming from the proxy’s IP address. You’re invisible at Layer 4.
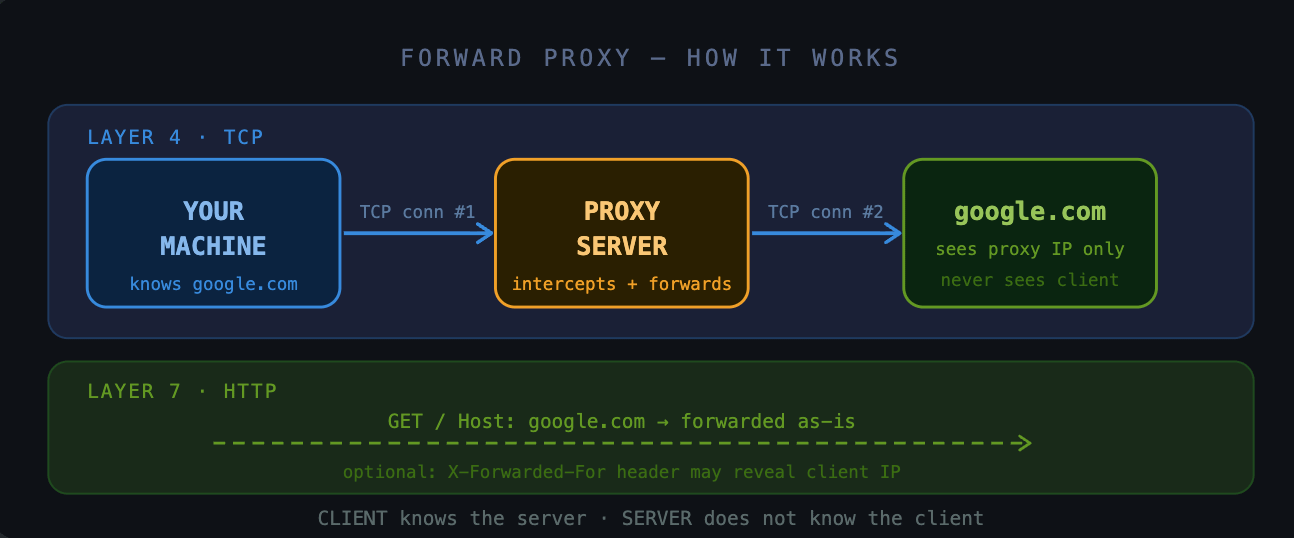
The content of your request gets forwarded as-is. Some proxies will add headers like X-Forwarded-For that could reveal your IP at the application layer — but from the raw network perspective, Google only ever saw the proxy.
The complete definition: The client knows the server. The server does not know the client.
Why would you actually use this?
Anonymity — Your IP never reaches the destination. Useful when you don’t want to be identified — though you’re trusting the proxy itself with everything.
Caching — Corporate proxies cache static pages. If 50 people in the same office request the same asset, the proxy serves it from memory after the first hit—no round trip to the origin.
Logging & observability — Every outbound request flows through one place. You can measure latency, trace failures, and monitor traffic patterns centrally — without touching application code.
Content filtering — The proxy sees every site your machine visits. Organizations use this to block sites — the proxy intercepts the request before it goes anywhere.
Debugging — Tools like Fiddler and Charles Proxy are literally proxies. They install on your machine, intercept all HTTP traffic, and let you inspect every request your app sends. This is how you debug a mobile app’s network calls.
Service mesh/sidecar — Envoy, Linkerd, Istio — run as proxy processes alongside your application. Every request your service makes routes through the sidecar first. Logging, tracing, circuit breaking — all handled there, without a single line of application code.
The entire service mesh pattern is built on the proxy concept. You deploy a small proxy alongside every service instance. It doesn’t change what your service does. It just sits in the middle and observes everything.
What is a reverse proxy?
Now flip it.
Definition: A reverse proxy receives requests on behalf of a backend. The client doesn’t know the true final destination. The backend doesn’t know the client.
You type google.com into your browser. Your TCP connection lands at a Google server. That server is a reverse proxy. It looks at your request and forwards it to one of hundreds of actual backend servers behind it — servers you will never know about and never directly address.
You think you’re talking to google.com. You are. But google.com it is a facade.
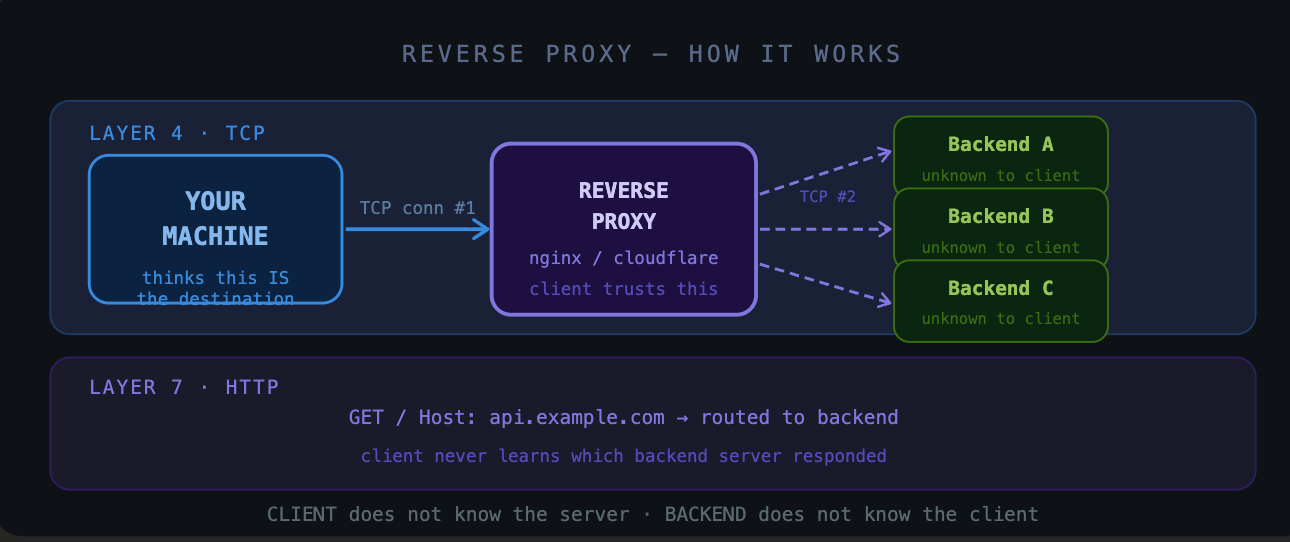
The distinction that trips everyone up
With a forward proxy, you configure it yourself. You open your system settings, enter a proxy address, and every request is routed through it. You know it’s there.
With a reverse proxy, you never configure anything. You go to a URL. The proxy is invisible server-side infrastructure you have no visibility into, which is precisely the point.
Why reverse proxies are one of the most powerful patterns in backend engineering
Once you have a single entry point the client trusts as the final destination, you can do almost anything behind it.
Think of a hotel concierge. You walk in and ask for something. You don’t know who they call. You don’t know which vendor they use or whether they’re routing your request to an in-house team or outside service. You asked the concierge. The concierge handles the rest. That’s a reverse proxy.
Load balancing
You hit api.stripe.com. Behind that, there are dozens of servers. The reverse proxy picks one — maybe round-robin, or based on which server is least loaded — and forwards your request to that server. The next person who hits api.stripe.com might land on a completely different server. Neither of you knows.
Every load balancer is a reverse proxy. Not every reverse proxy is a load balancer. Load balancing is one use case. The reverse proxy is the mechanism.
API gateways
Say you’re building a microservices backend. You have separate services for authentication, posting, and reading a feed. Each runs on its own servers with its own database. A reverse proxy in front of all of them routes based on the URL path:
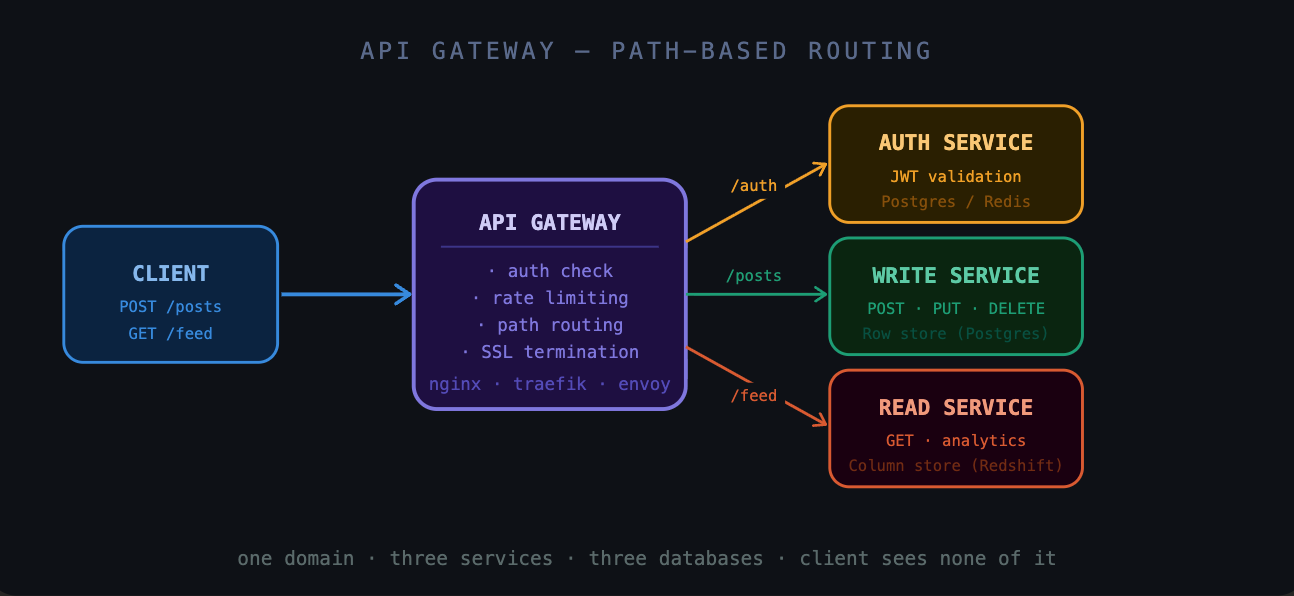
POST /auth→ Auth service (Postgres)POST /posts→ Write service (row store)GET /feed→ Read service (column store)
The write service might talk to a row store. The read/analytics service might use a columnar database. The client makes HTTP calls to a single domain and is unaware that any of this exists.
CDNs — a “glorified reverse proxy.”
A content delivery network like Fastly or Cloudflare is, at its core, a reverse proxy with caching and geographic distribution bolted on.
You request India. Instead of your TCP connection traveling to a US data center, it lands at a CDN node physically close to you — maybe in Mumbai. That node serves you cached content. If it doesn’t have it cached, it fetches from the origin. You never knew.
This is also why CDNs are fundamentally different from forward-proxy caching. A corporate proxy caches on behalf of the client you configured. A CDN caches on behalf of the server. The origin decided to put content on a CDN. Classic reverse proxy pattern.
Canary deployments
You want to test a new feature without breaking things for everyone. A reverse proxy lets you split traffic: route 10% to the new server version, 90% to the stable one.
Watch your error rates. If nothing explodes, gradually increase the percentage.
This only works if your application is stateless. A user’s second request might land on a different server than their first. The proxy doesn’t care about session continuity — that’s your problem to solve at the application layer.
Proxy vs. Reverse Proxy — side by side
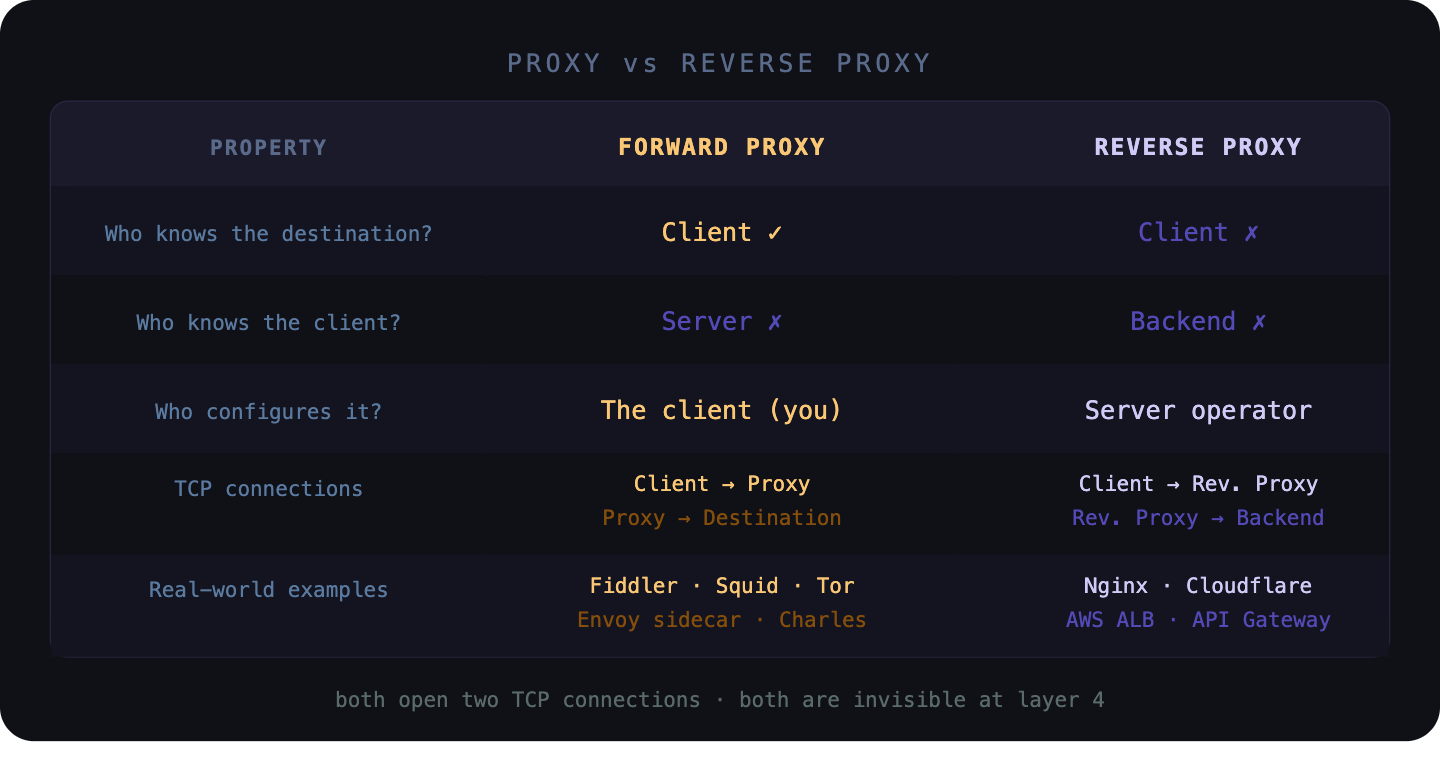
Questions engineers always ask
Can you use both simultaneously?
Yes — and it happens constantly in production. Your browser might be configured to send all traffic through a corporate proxy. That proxy forwards to api.example.com. That domain is a reverse proxy that routes to a backend microservice you’ll never know exists.
Three hops. You only configured the first one.
Is a proxy good enough instead of a VPN?
Not really. A VPN operates at the IP layer — it encrypts raw IP packets and doesn’t need to understand the protocol inside them. A proxy operates at Layer 4 and above, which means it must understand your protocol.
The bigger issue: many proxies terminate TLS and inspect your traffic. They decrypt the HTTPS request, inspect the content, then re-encrypt it. If anonymity is your goal, that proxy just saw everything. VPNs don’t do that.
Is the HTTP proxy only for HTTP?
Mostly yes, but there’s a tunnel mode. When an HTTP proxy receives CONNECT google.com:443, it opens a raw TCP connection to that destination and becomes a dumb pipe — passing bytes through without looking at them. This lets you run end-to-end TLS through an HTTP proxy without the proxy decrypting anything. That’s why your browser can reach HTTPS sites through an HTTP proxy.
What this unlocks for your mental model
Once you internalize the proxy vs. reverse proxy distinction, a lot of things that sounded complicated just become instances of this pattern:
Load balancers = reverse proxies that distribute traffic
CDNs = reverse proxies with geographic caching
API gateways = reverse proxies with routing and auth
Service mesh sidecars = forward proxies deployed per-service
Kubernetes ingress controllers = reverse proxies
Every one of those things, when you strip away the marketing, is: a server that sits between two other servers and makes decisions about what gets forwarded where.
The two variants differ in one thing — which side knows the other’s true identity.
Key takeaways
✓ A proxy hides the client from the server. You configure it. The server never knows who you are at Layer 4.
✓ A reverse proxy hides the server from the client. The server operator configures it. You never know what’s behind it.
✓ Both terminate the TCP connection and open a new one on the other side. That’s the mechanism everything else is built on.
✓ Load balancers, CDNs, API gateways, and ingress controllers are all reverse proxies with different features layered on top.
✓ Service mesh sidecars are forward proxies deployed per-service for observability and control.
✓ You can — and often are — using both simultaneously without realizing it.